Benzinga의 인프라는 99.9% 가용성을 보장하도록 설계되어, 애플리케이션이 24시간 실시간 금융 데이터를 안정적으로 수신할 수 있도록 합니다. 프로덕션 환경은 실전에서 검증되었으며, 완전한 모니터링과 주 5일 24시간 온콜 엔지니어링 지원으로 뒷받침됩니다.
개요
99.9% 가동률 SLA
다중 AZ 이중화를 통한 검증된 프로덕션 안정성
24/7 모니터링
Coralogix 및 Datadog 기반 실시간 가시성
자동 확장
지능형 오토스케일링을 통한 무중단 배포
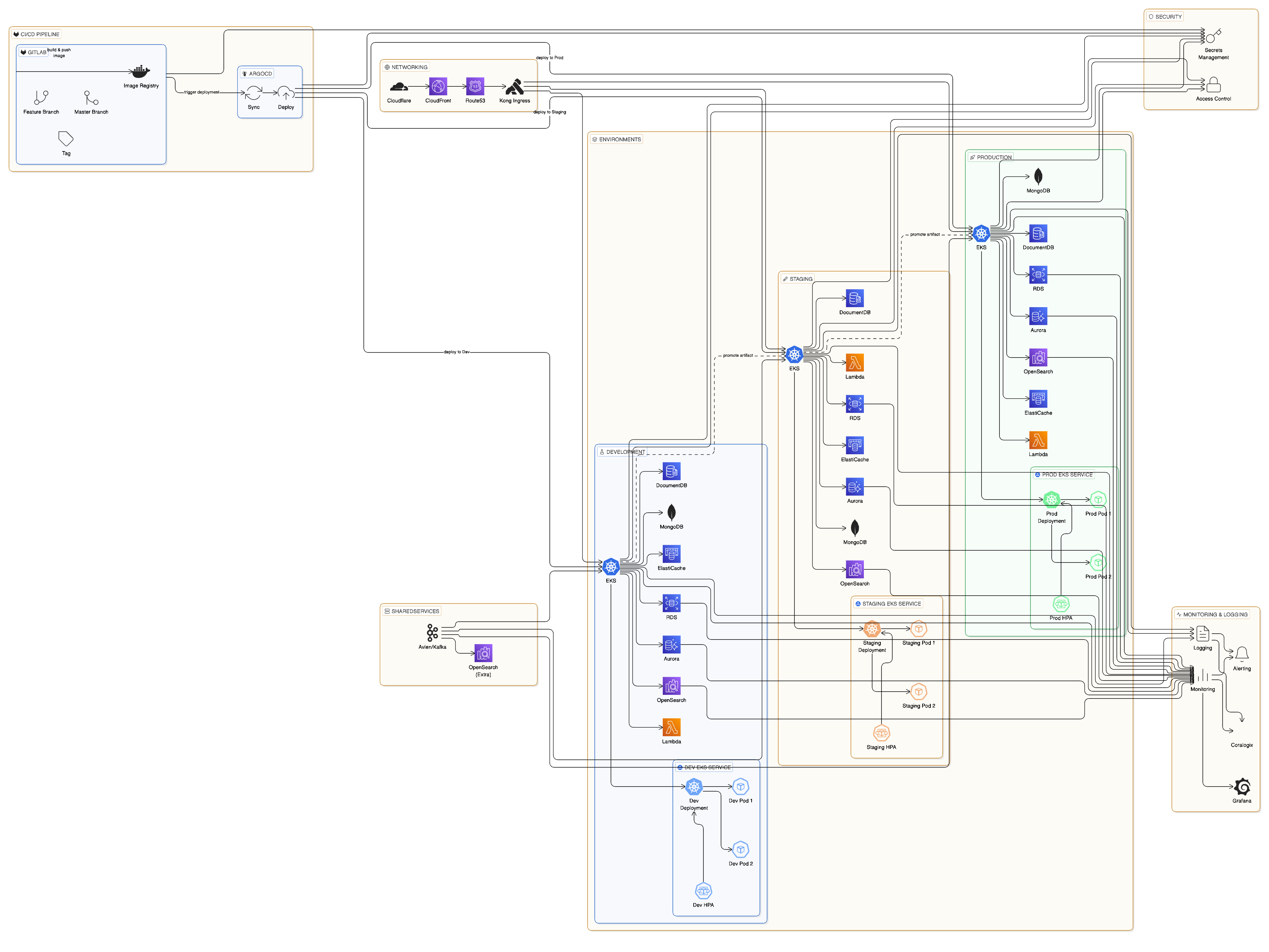
핵심 인프라
AWS 클라우드 기반
Multi-AZ Deployment
장애 허용성을 위해 여러 가용 영역(Availability Zone)에 서비스를 배포합니다
AWS VPC
엄격한 보안 그룹 정책이 적용된 격리된 Virtual Private Cloud
Route 53
상태 점검(Health Check)과 자동 장애 조치 라우팅을 지원하는 글로벌 DNS
Managed EKS
AWS에서 관리되는 Kubernetes 제어 플레인으로 99.95% SLA 제공
Kubernetes 인프라
| 환경 | 목적 | 배포 흐름 |
|---|---|---|
| Staging 클러스터 | 개발자 테스트, QA 검증, 통합 테스트 | 코드 변경 사항을 먼저 배포해 검증 |
| Production 클러스터 | SLA가 보장되는 실시간 고객 트래픽 처리 | 검증된 릴리스만 승격 |
주요 Kubernetes 컴포넌트
- Karpenter — 분 단위가 아닌 수 초 만에 적정 규모의 컴퓨팅 리소스를 프로비저닝하는 AWS 네이티브 노드 오토스케일러
- Horizontal Pod Autoscaler (HPA) — CPU, 메모리 및 사용자 정의 메트릭 기반의 자동 Pod 스케일링
- Kong Gateway — 인그레스/이그레스, 요청 속도 제한(rate limiting), 인증을 처리하는 엔터프라이즈급 API 게이트웨이
- ArgoCD — 선언적이고 감사 추적이 가능한 릴리스를 위한 GitOps 기반 배포 컨트롤러
API 게이트웨이 및 트래픽 관리
Kong Gateway
Route 53 DNS
- 글로벌 지연 시간 기반 라우팅 — 사용자가 자동으로 가장 빠른 엔드포인트로 라우팅됨
- 헬스 체크 — 장애 발생 시 자동 장애 조치를 포함한 지속적인 모니터링
- 100% 가동 시간 SLA — DNS 해석에 대해 AWS가 보증하는 가용성
CI/CD 파이프라인
개발 워크플로
파이프라인 단계
| 단계 | 설명 | 품질 게이트 |
|---|---|---|
| Lint | 코드 스타일 및 정적 분석 검사 | 모든 규칙 통과 필수 |
| Unit Tests | 자동화된 테스트 스위트 실행 | 100% 테스트 통과 |
| Security Scan | 컨테이너 취약점 스캔 | 치명적/높은 심각도의 CVE 없음 |
| Build | 커밋 SHA로 태그된 Docker 이미지 생성 | 빌드 성공 |
| Peer Review | 2명의 개발자가 수행하는 수동 코드 리뷰 | 두 명의 승인 필요 |
| GitOps Update | ArgoCD 리포지토리에서 이미지 태그 업데이트 | 수동 승급 |
ArgoCD를 사용한 GitOps
- 선언적(Declarative) — 원하는 상태를 Git에 정의하고 이를 단일 신뢰 소스로 사용
- 자동 동기화(Automated sync) — ArgoCD가 변경 사항을 감지하고 자동으로 적용
- 롤백 기능(Rollback capability) — Git 커밋을 되돌려 즉시 롤백 가능
- 감사 추적(Audit trail) — Git 커밋 로그를 통해 전체 배포 이력 확인 가능
자동 확장 아키텍처
Pod 수준 스케일링 (HPA)
- CPU 사용률 > 70%
- 메모리 사용률 > 80%
- 사용자 정의 지표(요청 큐 깊이, 지연 시간 백분위수)
노드 수준 스케일링 (Karpenter)
- 60초 이내에 최적 크기의 노드를 프로비저닝합니다
- 비용 절감을 위해 저활용 노드를 통합합니다
- 비핵심 워크로드에 대해 스팟 인스턴스를 지원합니다
- 파드 토폴로지 및 가용 영역 제약 조건을 준수합니다
프로덕션 수준의 오브저버빌리티 및 모니터링
포괄적인 모니터링 스택
Coralogix
분산 트레이싱 및 로깅
- 모든 서비스의 실시간 로그 수집
- 마이크로서비스 전반에 대한 분산 트레이싱
- 애플리케이션 성능 모니터링(APM)
- Correlation ID를 통한 엔드 투 엔드 요청 추적
- 로그 패턴 인식 및 이상 감지
- 비즈니스 지표용 사용자 정의 대시보드
Datadog
알림 및 합성 모니터링
- 24/7 지속적인 API 엔드포인트 테스트
- 다중 리전 합성 모니터링
- 응답 시간 및 가용성 추적
- 지능형 라우팅을 통한 자동 알림
- 서비스 수준 지표(SLI) 추적
- 성능 회귀(regression) 감지
Coralogix: 트레이싱 및 로깅
분산 트레이싱
모든 API 요청을 마이크로서비스, 로드 밸런서, 데이터베이스, 외부 서비스 전 구간에 걸쳐 엔드투엔드로 추적합니다. 이를 통해 성능 문제나 오류의 근본 원인을 신속하게 분석할 수 있습니다.
- 보관 정책(Retention Policy): 즉시 조회를 위한 30일 핫 스토리지, 규제 준수를 위한 90일 아카이브
- 쿼리 성능: 수십억 건의 로그 항목에 대해 1초 미만 응답의 쿼리 처리
- 알림 연동: Slack 채널 및 온콜 담당 엔지니어에게 자동 라우팅
- 커스텀 대시보드: 비즈니스별 메트릭을 이해관계자가 실시간으로 확인 가능
Datadog: 알림 및 Synthetics
Synthetic API Testing
자동화된 테스트가 여러 지리적 리전에서 60초마다 실행되어, 고객에게 문제가 발생하기 전에 API 가용성, 응답 시간, 데이터 정확성을 검증합니다.
| 테스트 유형 | 빈도 | 리전 | 모니터링 메트릭 |
|---|---|---|---|
| API 상태 점검(Health Check) | 60초마다 | 전 세계 5개 리전 | 가용성, 응답 시간, 상태 코드 |
| 데이터 정확성 테스트 | 5분마다 | 3개 리전 | 데이터 최신성, 스키마 검증, 무결성 |
| 성능 테스트 | 60초마다 | 5개 리전 | 지연 시간(p50/p95/p99), 처리량, 오류율 |
| 인증 테스트 | 5분마다 | 2개 리전 | API 키 검증, 요청 제한(rate limiting), OAuth 플로우 |
Slack 연동 & 인시던트 관리
#alerts-production
중요 알림
- 즉각적인 조치가 필요한 P1/P2 등급 인시던트
- 온콜 엔지니어 자동 호출
- 실시간 메트릭 및 런북 링크
- 인시던트 커맨더 배정
#monitoring-insights
성능 인사이트
- 일일 상태 요약
- 용량 계획 관련 알림
- 성능 추세 알림
- 이상 탐지 경고
알림 및 인시던트
- 알림 발생 → 컨텍스트와 메트릭이 포함된 자동 Slack 알림 전송
- 온콜 엔지니어 트리아지 → 심각도 평가 및 인시던트 채널 생성
- 개발자 배정 → 영향받은 서비스 기준으로 담당 전문가 태깅
- 조사 → Coralogix 트레이스와 Datadog 메트릭을 활용한 근본 원인 분석
- 해결 → 표준 GitOps 파이프라인을 통한 수정 사항 배포
- 사후 분석(Post-Mortem) → 예방 조치를 포함한 인시던트 문서화
보안 및 컴플라이언스
네트워크 보안
- VPC 격리 — 퍼블릭 인터넷으로부터 완전한 네트워크 분리
- 보안 그룹(Security Groups) — 엄격한 인바운드/아웃바운드 규칙, 기본 거부(deny-by-default) 정책
- 전 구간 TLS(TLS Everywhere) — 모든 내부 및 외부 트래픽을 암호화
- 시크릿 관리(Secrets Management) — 민감한 자격 증명을 AWS Secrets Manager로 관리
액세스 제어
- RBAC — 모든 작업에 대한 Kubernetes 역할 기반 액세스 제어
- SSO 통합 — 엔터프라이즈 ID 공급자(Identity Provider) 연동
- 감사 로깅 — 규정 준수를 위해 보존되는 전체 액세스 로그
재해 복구
복구 목표
| 지표 | 목표 | 현재 |
|---|---|---|
| RTO (Recovery Time Objective) | < 15분 | 약 5분 |
| RPO (Recovery Point Objective) | < 1분 | 실시간 복제 |
탄력성 기능
- 다중 AZ 복제 — 가용 영역 간 데이터 복제
- 자동 장애 조치 — Route 53 상태 검사로 DNS 장애 조치 수행
- 롤링 배포 — 자동 롤백을 지원하는 무중단 배포
- 백업 및 복구 — 지정 시점 복구(Point-in-Time Recovery)가 가능한 일일 자동 백업
프로덕션 환경급 신뢰성 보장
우리의 인프라가 견고한 이유
대규모 환경에서 검증 완료
프로덕션 통계
- 하루 1,000만 건 이상의 API 요청 처리
- 평균 응답 시간 100ms 미만
- 99.9%의 누적 가용성 달성
- 3년 이상 데이터 손실 0건
엔터프라이즈급 운영
운영 우수성
- 연중 평일 24시간 온콜 엔지니어 지원
- 자동 페일오버 및 자가 복구
- 멀티 리전 이중화 구성
모니터링 및 옵저버빌리티
고객 신뢰: 이것이 여러분에게 의미하는 바
| Feature | Client Benefit |
|---|---|
| Multi-AZ Redundancy | AWS 가용 영역(Availability Zone) 장애가 발생해도 애플리케이션이 온라인 상태를 유지합니다 |
| Automated Scaling | 트래픽 급증 시에도 요청 제한 없이 요청이 원활하게 처리됩니다 |
| 24/7 Monitoring | 성능 저하를 인지하기 전에 엔지니어가 문제를 감지하고 해결합니다 |
| Zero-Downtime Deployments | 업데이트로 인해 서비스 가용성이 중단되지 않습니다 |
| Complete Audit Trail | 모든 배포가 추적·검토되며, 즉시 롤백이 가능합니다 |
| Proactive Alerting | 고객에게 영향이 가기 전에 잠재적인 문제의 95%가 해결됩니다 |
프로덕션 준비 완료: 당사의 인프라는 수십억 건의 API 요청을 처리하면서 99.9% 가용성을 유지해 왔으며, 실시간 금융 데이터 전송 시 100ms 미만의 지연 시간을 유지합니다.
요약
고객 성공이 최우선입니다: 인프라, SLA 보장 사항 또는 귀사의 구체적인 신뢰성 요구 사항 논의와 관련된 문의는 담당 어카운트 매니저에게 연락하시거나 support@benzinga.com으로 이메일을 보내주시기 바랍니다.